Как узнать семантику конкурентов?
Ссылка на инструмент подбора семантического ядра по сайту: https://arsenkin.ru/tools/semantics/
API на инструмент: https://help.arsenkin.ru/api/semantics-url-domain
Если вам нужно проанализировать семантику по конкуренту или определенному сайту, вам поможет наш инструмент. Ниже расскажем, как работать с инструментом анализа семантического ядра.
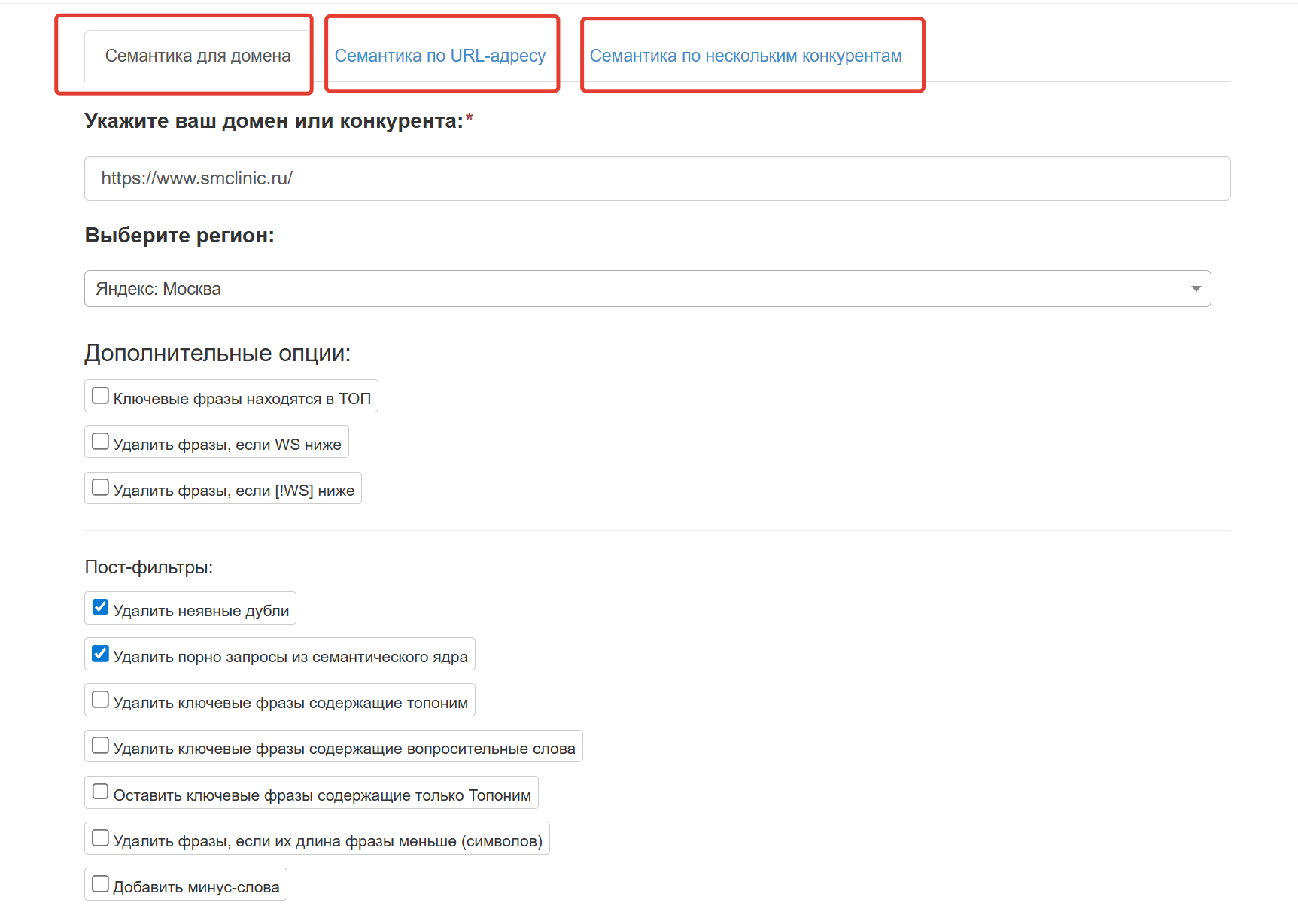
Инструмент имеет три режима сбора семантического ядра:
- Семантика для домена - для этого режима необходимо указать домен сайта и выбрать регион из ограниченного списка городов. Затем инструмент подберет семантическое ядро для указанного сайта, основываясь на его видимости в поисковых системах и полноте базы партнера.
- Семантика по URL-адресу - в данном режиме возможно формирование семантического ядра для конкретной страницы.
- Семантика по нескольким конкурентам - этот режим предоставляет возможность собрать семантику на основе ваших конкурентов. Вы указываете список доменов конкурентов, выбираете дополнительные опции, и в короткие сроки получаете семантику для своего сайта.
Обзор функционала
Перед стартом анализа введите свой домен или сайт конкурента в поле «Укажите ваш домен или конкурента» и выберите регион. Это поможет системе подготовить точные данные именно для вашего рынка.
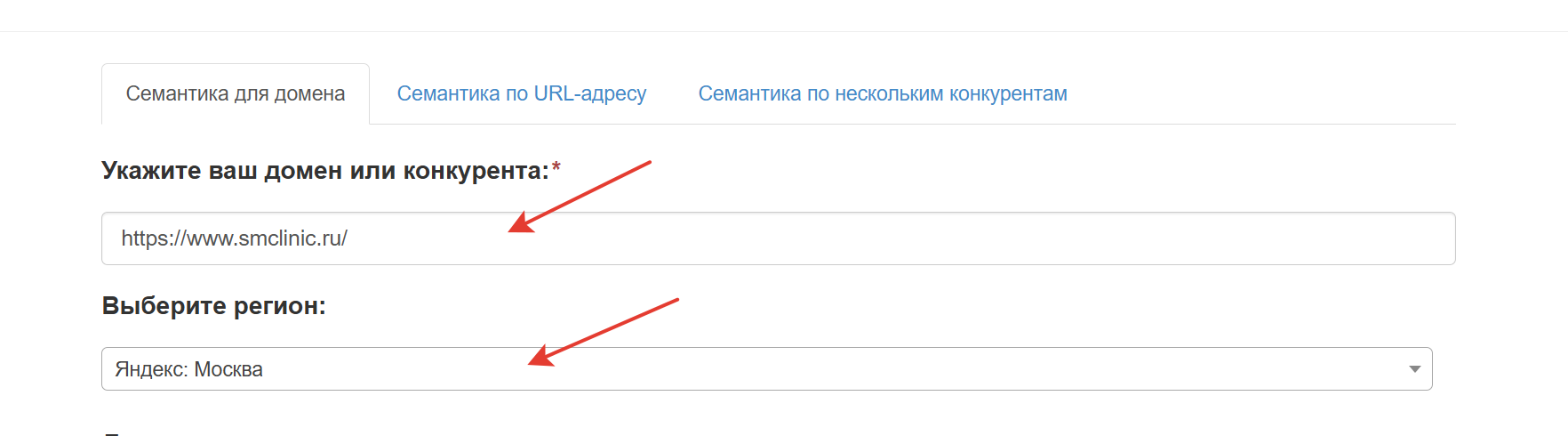
Количество доступных регионов ограничено, так как для определения семантики используется готовая база данных нашего партнёра — keys.so. Инструмент работает в связке с этой базой.
Если вам нужны свежие данные, то используйте инструменты парсинга Яндекс Вордстат и парсинг поисковых подсказок.
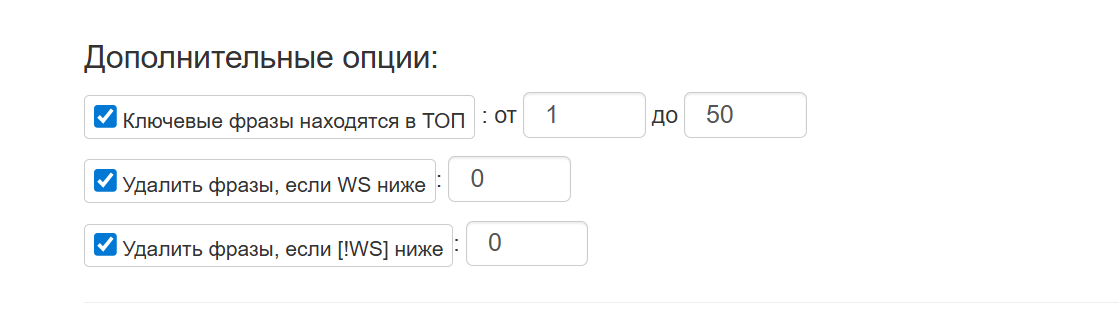
Дополнительные опции. Вы можете задать правила фильтрации выгружаемых данных, чтобы получать только нужные ключевые фразы. Например:
- Ключевые фразы находятся в ТОП. Выберите ключевые фразы, которые находятся только в топ-10, топ-20 и т.д. Для этого введите соответствующее число (например, 10), и инструмент включит только те фразы, которые находятся в указанном диапазоне.
- Удаляйте фразы, если их WS (частота) ниже заданного значения. Например, чтобы исключить ключевые фразы с частотой ниже 100, укажите число 100.
- Исключайте фразы с низкой частотой с учётом порядка слов. Например, чтобы убрать ключевые фразы с [!WS] ниже 5, задайте это значение в соответствующем поле.
Пост-фильтры помогают дополнительно очистить семантическое ядро, чтобы на выходе оставались только релевантные ключевые фразы. Часто готовые базы включают фразы, не относящиеся к текущему проекту, и пост-фильтры позволяют их удалять.
- Удалить неявные дубли. Позволяет удалить фразы с переставленными словами, которые имеют одинаковый смысл. Например, [заказать металлическую дверь] и [металлическую дверь заказать] будут объединены.
- Удалить порно запросы. Удаляет фразы с контентом для взрослых. База таких запросов обновляется регулярно для эффективного фильтрования.
- Удалить ключевые фразы содержащие топонимы. Очищает ядро от фраз с названиями городов и населённых пунктов (Москва, СПБ, МСК и т.д.). База топонимов обновляется автоматически.
- Удалить ключевые фразы содержащие вопросительные слова. Исключает фразы с «где», «как», «почему» и другими вопросительными словами. Обратите внимание: в коммерческих тематиках такие слова могут быть полезны (например, [где купить чемодан в Москве]).
- Оставить ключевые фраз содержащие только топоним. Формирует ядро только из фраз, содержащих названия местоположений.
- Удалить фразы, если их длина фразы меньше (символов): N. Исключает ключевые фразы короче заданного числа символов, например 2–3 символа.
- Добавить минус-слова для чистки. Позволяет указать слова для исключения, вводя каждое с новой строки.

После того как вы указали домен и настроили все опции, запустите анализ и выгрузку данных. Вы увидите прогресс-бар, который покажет ход выполнения процесса.

После завершения анализа вы получите результаты проверки. Ключевые фразы не отображаются напрямую в интерфейсе, но их можно скачать в формате Excel для дальнейшей работы и анализа.
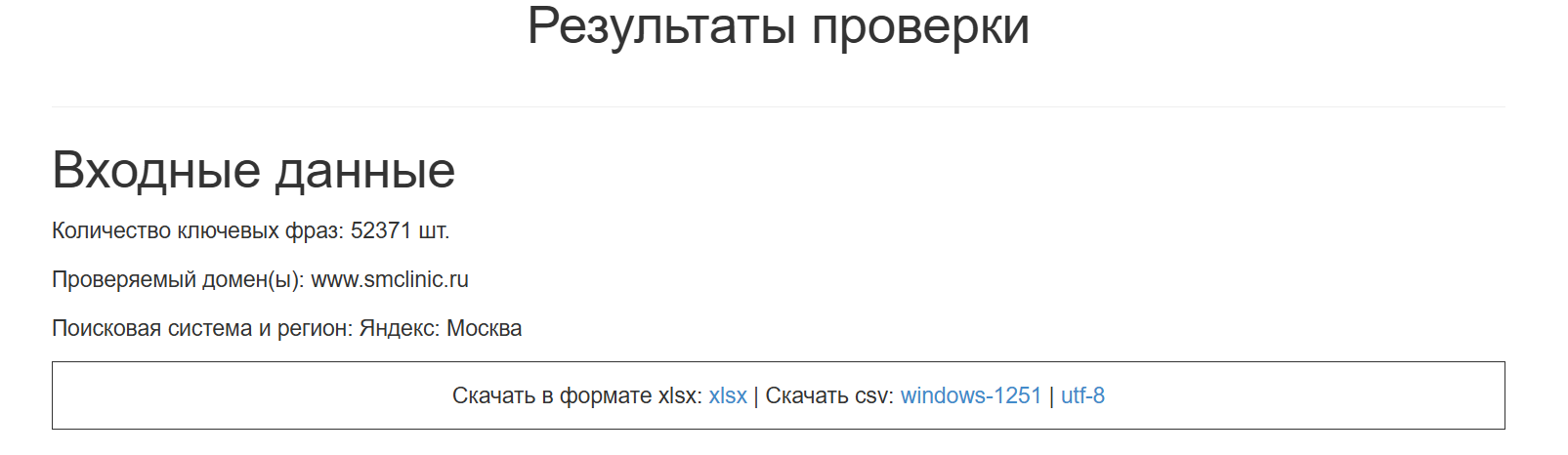
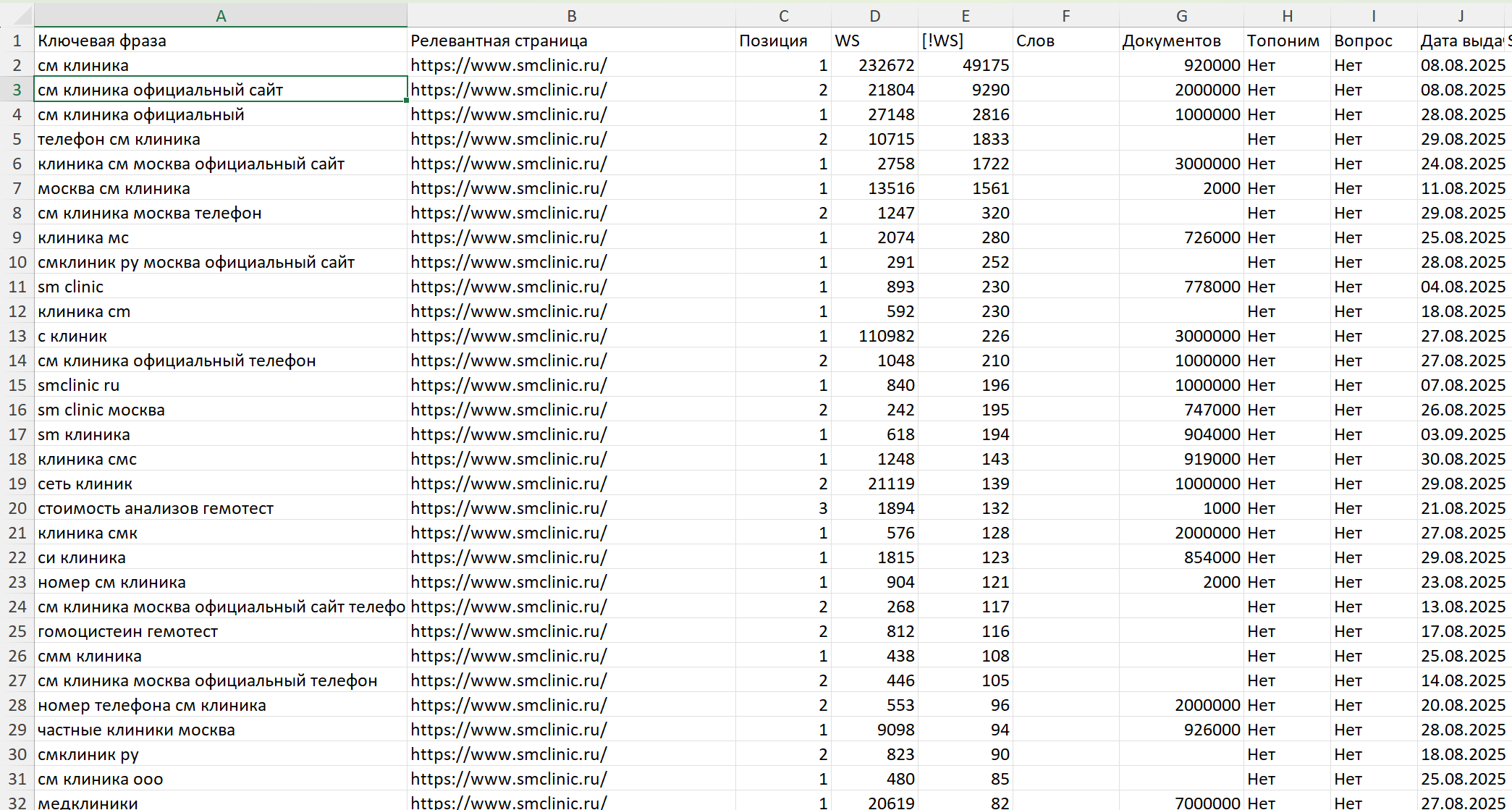
Результат в Excel. Выгруженный файл содержит следующие данные:
- Ключевая фраза
- Релевантная страница
- Позиция на дату сбора выдачи
- Общая частота (WS)
- Уточненная частота ([!WS])
- Найденных документов
- В фразе имеется ли топоним
- В фразе имеется ли вопросительное слово
- Дата сбора данных для фразы.
Файл Excel позволяет легко анализировать и фильтровать ключевые фразы для дальнейшей работы.
Итого
Собрать и очистить семантическое ядро — ключевой шаг для успешного продвижения сайта. С нашим инструментом вы получаете не просто список ключевых фраз, а тщательно обработанные данные, готовые к анализу и использованию.
Вы можете:
-
фильтровать фразы по позиции в выдаче и частоте запросов;
-
удалять дубли, нежелательные и нерелевантные запросы;
-
работать с топонимами и вопросительными словами для более точной семантики;
-
экспортировать результаты в Excel для дальнейшей аналитики.
Благодаря этим возможностям вы экономите время и ресурсы, избегаете ручной обработки больших объёмов данных и получаете чистое, релевантное семантическое ядро, готовое для SEO-продвижения, контент-планирования или маркетингового анализа.
Помните, что качественная семантика — это фундамент, на котором строится эффективная стратегия продвижения. Настройте фильтры, запустите анализ и получите данные, которые действительно работают на результат.
Не откладывайте на потом: начните анализ уже сегодня и убедитесь, как легко превратить огромные массивы данных в конкретные действия для роста вашего проекта.